


Bagged, Tagged, and Identified: The Future of Self-Checkout with AI





Team Members
Eshaan Arora (ea33245), Greeshma Gopinathan (gg33287), Ronak Goyal (rg49394), Areeba Shah (as235948), & Felipe Zapater (fz2852)
Project Code
The code written for this project can be found here.
Abstract
The increasing reliance on self-checkout systems in grocery stores has brought convenience to shoppers but also exposed significant challenges, especially with non-barcoded items such as fruits and vegetables. Non-barcoded items pose the significant issue of inefficiency at the checkout line, due to the manual nature of its process. Customers often face frustration with long checkout times due to this issue, while stores experience shrinkage and financial losses due to the manual misclassification of items at the self checkout counters. We aim to enhance the self checkout process by streamlining the handling of non barcoded items, improving customer satisfaction while minimizing shrinkage costs.
In this blog, we present ScanSense AI, which is a cutting-edge machine learning solution primarily designed to identify grocery items, including those in plastic bags, which often pose unique challenges. With the help of Convolutional Neural Networks (CNNs), fine-tuned ResNet models, and extensive data augmentation techniques, our model demonstrates robust performance even in scenarios with blurriness or distortion caused by packaging.
Introduction & Background
Self checkout systems have revolutionized modern grocery shopping by offering speed and convenience to both customers and the stores alike. However, with non-barcoded items such as fruits and vegetables, these systems and processes often fall short. Customers find themselves manually scrolling through confusing menus or dealing with error prone systems, causing delays in the checkout process and thus, damaging the customers experience.
For grocery stores, the stakes are higher. Misclassification at the self checkout line can result in significant financial losses through the combination of human error, incorrect pricing, and theft. For instance, a customer might mistakenly (or deliberately) classify an avocado as a less expensive zucchini. While each individual error may seem negligible, these small losses compound, leading to millions of dollars in revenue lost annually. The figure below illustrates statistics about 20.1 million Americans who have inadvertently and intentionally stolen from stores at the Self Checkout lane. This shrinkage problem clearly reflects the need for innovation in self checkout lanes.

Figure 1: Shrinkage in Self Checkout Lanes.
More and more traditional systems are being converted to self checkout systems, so the problem will amplify. Addressing the inefficiencies with non-barcoded items is not just a minor adjustment, it is critical for reducing shrinkage and enhancing customer satisfaction at the checkout line. ScanSense AI aims to fill this gap by providing a smarter and more efficient solution to the traditional self checkout approach. By leveraging Machine Learning models, including Convolutional Neural Networks and ResNet models, our model will aim to accurately identify non barcoded items, even when distorted by poor light quality or covered by a plastic. This approach will aim to enhance the customer experience, by reducing wait times and manual efforts, and help mitigate the shrinkage problem plaguing grocery stores.
Related Work
Amazon has made tremendous strides in this space with technologies like "Just Walk Out." Announced in 2016, this system leverages advanced AI and computer vision to create a frictionless shopping experience where customers simply grab items and leave, with receipts generated automatically. However, such solutions are costly to implement and rely heavily on infrastructure that many stores can not afford.
Traditional self checkout systems, meanwhile, focus on barcode scanning and fail to adequately address the unique challenges of non barcoded items. This gap highlights the need for a cost effective solution that can address the challenges of traditional infrastructure without replacing the entire functionality of the system themselves. By leveraging advanced ML models and data augmentation techniques, ScanSense AI can help bridge this gap, enabling accurate classification of non barcode items in real world environments.
Outline of Approach
At the core of ScanSense AI is a robust machine learning system that is built on model refinement. A Convolutional Neural Network (CNN) was initially deployed to classify grocery store items, but it struggled with accurate classification, especially in challenging conditions. To address this shortfall, we transitioned to a ResNet model, leveraging its deeper architecture and enhanced feature extraction capabilities. We further enhanced this model by introducing scenarios like blurriness, rotations, cropping, and plastic bag obstructions to simulate real world environments. Further, to mitigate the financial costs of misclassification, we implemented a fallback approach that ensures customers are not overcharged if the model has struggled with confidently predicting a non barcoded item. This approach ensures customer satisfaction by prioritizing fair pricing while initially shifting some of the misclassification costs to the store. However, as the model iteratively learns from these errors and improves its accuracy over time, these shrinkage costs are expected to diminish, benefiting both the customer experience and the store's margins.
Novel Characteristics
ScanSense AI stands out for its innovative and practical approach addressing the complex challenges with non-barcoded item classification. Through the incorporation of data augmentation techniques, the system can handle blurred and distorted images, including those covered by plastic bag layers in the self checkout lane. This allows for reliable real world classification where traditional systems may potentially struggle.
The inclusion of the cost aware fallback mechanism further sets ScanSense AI apart. When the model lacks the confidence in its prediction, it defaults to a safer item classification that prevents customers from being overcharged. While this initially shifts some of the financial losses on to the store through increased shrinkage costs, the hope is that the system can improve and learn iteratively based on the misclassifications it has had in the past.
Data Overview: The Backbone of ScanSense AI
Introduction to Dataset
To address the issue with non barcoded grocery items at checkout, we decided to employ a data set from Kaggle that featured 36 different classes of fruits and vegetables. The dataset was organized into three sets; train images, test images, and validation images. Each set contained 36 subfolders of different fruits and vegetable classes. A summarized overview of the dataset distribution is as follows:
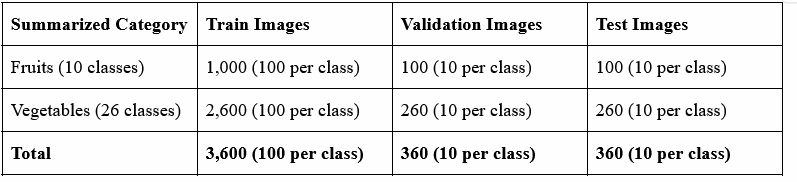
This balanced dataset ensures the model was trained, validated, and tested on different produce. The goal of using this balanced variety is to ensure that the model is equipped to handle real world grocery scenarios with accuracy and reliability. This data set covered a diverse range of fruits and vegetable sizes, shapes, and colors. The ability for the model to be able to generalize well is of paramount importance. We excluded duplicate classes to avoid misclassifications. (Corn vs. sweet corn, Bell pepper vs. capsicum)
Example Images

Figure 2: Images from Dataset.
Data Preprocessing: Refining the Raw Input
Our preprocessing approach focused on ensuring consistency, simulating real-world variability, and enhancing image quality for better classification. We focused on three key steps in our data preprocessing; resizing the images, data augmentation, and image segmentation.
Step 1: Resizing for Consistency
Before anything else, ensuring consistent image dimensions across the dataset was key. All images were resized to 256x256 pixels and cropped to 224x224. This step standardized the input for ResNet, the backbone of our classification system, allowing the model to focus on learning key patterns instead of compensating for size discrepancies.

Figure 3: Snippet of Preprocessing Code.
Step 2: Data Augmentation for Real-World Variability
In real world grocery stores, the appearance of produce can vary due to lighting, orientation, packaging, and partial obstructions. To account for these challenges, we implemented a range of data augmentation techniques. These augmentations enhanced our dataset, making the model more robust to unpredictable conditions.
Key techniques included:
Random Rotations and Flips: Simulated produce in different orientations.
Brightness Adjustments: Mimicked varied store lighting.
Zoom and Crop: Created scenarios of partial occlusion.
Gaussian Blur: Simulated distortions caused by plastic bags.
The figure on the left below (Figure 4) is an example of an unaltered image from our original data set. Through the alteration process outlined above, this image of a carrot was transformed into the resulting image shown on the right (Figure 5).


Figures 4 and 5: Original image and augmented image.
Step 3: Image Segmentation
Beyond resizing and augmentation, we went a step further by isolating the produce itself from the background. Leveraging OpenCV image processing library which does image segmentation using HSV(Hue, Saturation, Value) components of an image, we highlighted the key features of each item while removing irrelevant details like shadows or checkout counters.
We used the HSV color space to identify and isolate specific color ranges unique to each type of produce. For instance, green hues were targeted for cucumbers, while orange tones were isolated for carrots. After isolating these regions, binary masks were applied to create a clear focus on the produce, and additional operations were used to eliminate noise and refine the segmented areas. This process ensured that the model's attention was directed solely at the produce, removing distractions like shadows or background noise.

Figure 6: Image Segmentation.
Through data collection, cleaning, and augmentation, we armed ScanSense AI with the tools it needed to excel. Each image became a piece of a larger puzzle, allowing the model to not just recognize a tomato but distinguish it from a similarly colored apple in a plastic bag.
The result? A system that thrives on the messy, unpredictable nature of real-world grocery checkouts.
Learning and Modeling: Building the Brains Behind ScanSense AI
When developing ScanSense AI, selecting the right model was critical to ensuring robust performance in real-world scenarios. We began with a Convolutional Neural Network (CNN) as our initial architecture. While CNN performed adequately on our training dataset, it struggled to generalize on unseen data, especially under challenging conditions like poor lighting or distortions caused by plastic bagging. This could be because of the limited data that was available to train the model. Based on our learnings from CNN, we explored other sophisticated architectures and landed with ResNet family of models.
Convolutional Neural Network (CNN)
We initially designed and implemented a bespoke, custom CNN model to tackle this problem. The key features of this model were as follows:
4 convolutional blocks with increasing feature maps (32, 64, 128, 256).
Dropout regularization (50%).
Modified fully connected layer for classification of n classes (number of classes based on dataset).
Relu activation function.
Batch normalization and max-pooling after each convolutional layer for stability and down-sampling.
Unfortunately, the performance of this CNN under real-world conditions revealed significant limitations. Despite leveraging comprehensive preprocessing techniques—such as resizing, normalization, and data augmentation to simulate real-world variability—the CNN struggled with complex scenarios like distorted images or occlusions caused by plastic bagging. These challenges highlighted the need for a model capable of extracting deeper features and generalizing more effectively. This prompted our transition to ResNet architecture, which proved to be a more robust solution for handling non-barcoded item classification in self-checkout systems.
Transition to ResNet Model
To address the limitations of the CNN, we turned to the ResNet Model. The skip connections in the ResNet model allow information to flow more freely across the layers, making it a great option for deeper architectures. By fine tuning the ResNet model pretrained on ImageNet, we leveraged its ability to extract high level features while minimizing training time. This was a huge component of the project, as we did not have the computational power to train a more complicated model on more exhaustive data.
We modified the final fully connected layer of the ResNet to output 34 classes, corresponding to the fruits and vegetables in our dataset. Additional layers were added for fine-tuning:
Dense Layer (128 units): Acts as a bottleneck for learning compact, high-level features.
ReLU Activation: Introduces non linearity for better decision boundaries.
Dropout (p=0.5): Prevents overfitting by introducing regularization.
While data augmentation techniques were a critical component of preprocessing (as discussed earlier), the architectural improvements in the ResNet model allowed for better utilization of the augmented dataset. The introduction of a dynamic learning rate scheduler further fine tuned the training process by automatically reducing the learning rate when validation performance plateaued, enabling the model to focus on incremental improvements. Additionally, early stopping mechanisms were implemented to prevent overfitting, ensuring that the model maintained consistent performance across unseen data.
Results and Performance
The effectiveness of ResNet is evident in the validation accuracy graph, which shows a steady improvement across epochs. ResNet achieved a final validation accuracy of 78.6%, outperforming CNN across all metrics. The confusion matrix further demonstrates this improvement, with ResNet reducing misclassifications for challenging items like bagged produce and visually similar categories.
Validation Accuracy Graph
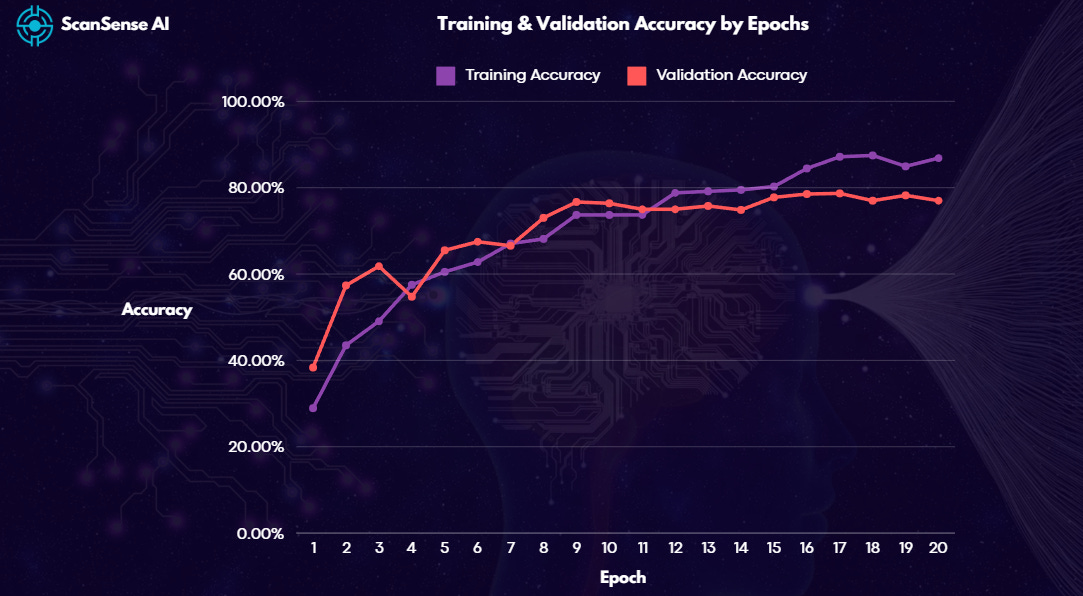
Figure 7: Validation Accuracy Graph.
Confusion Matrix
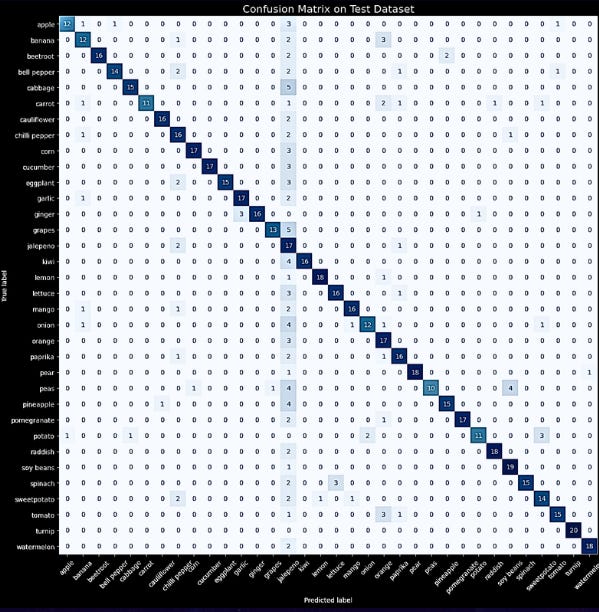
Figure 8: Confusion Matrix.
Misclassification Implications
One of the most practical aspects of ScanSense AI is its ability to handle the financial implications of misclassification. Like with many newer models deployed into production environments for the first time, ScanSense AI is not able to accurately classify all produce with 100% accuracy. This means that there will be some financial losses that will need to be absorbed by the grocery store as shrinkage costs, or by the customer.
To provide a clearer context of financial implications, it is important to take note of who is burdened by a misclassification by the model. If the model classifies a high value item as a cheaper item, then the store will lose revenue and its shrinkages are adversely affected. Conversely, if the model classifies a low value item as an expensive item, then the customer will be overcharged and will bear the additional costs imposed from misclassification.
The key thing to note is that we would like to limit the potential losses of the customer so their satisfaction is not affected. In order to achieve this goal, we have implemented a fallback threshold strategy that essentially gives the customer the benefit of the doubt when the model is unsure of its classification.
Cost Aware Fallback Strategy
The foundation for this logic is simple: we would like for the model to undercharge customers if the model is uncertain of classification for a given image. As such, if the model outputs a classification with a confidence under a minimum threshold (ie. 80%), then three alternative classifications are evaluated based on their price, and the model will predict the lowest price of this subset. In other words, the model will predict the cheapest item of all the closely related items so that the customer is not overcharged if the model is not confident in its precision.
As an example, the table below shows three different scenarios assuming a confidence threshold of 80%:

Figure 9: Misclassification Fallback Logic.
Scenario A: A Lemon is predicted to be a Lemon with a confidence of 85%. This is above the confidence threshold of 80% set, so no action is required to alter this prediction. The predicted class is still a lemon. (Fallback mechanism not activated)
Scenario B: A Lime is predicted to be a Lime with a confidence of 60%. This is below the confidence threshold of 60%, so the fallback mechanism is introduced. The three classes with the highest probabilities are analyzed, and the predicted class is chosen to be the lowest price of the top three class choices. In this scenario, the lime is the cheapest of the three classes, so the predicted class would still be a lime. However, if a lime were to be $2.06 as opposed to $2.00, the lime would have been classified as a lemon. (Fallback mechanism activated)
Scenario C: A Kiwi is predicted to be a Lemon with a confidence of 50%. Because the confidence is below the threshold of 80%, the fallback mechanism is activated. As such, the prices of the three alternatives are evaluated to determine which class to predict. In this case, since the lime is the cheapest option of the three classes, the Kiwi (originally predicted to be a lemon) is now classified as a lime (Fallback mechanism activated).
Results: Evaluating the Performance of ScanSense AI
After data collection, model training, and refining strategies, we tested the ScanSense AI Model on unseen product images to see how well the model would perform on the images.
Key Findings and Model Evaluation
While CNNs served as a foundational model for our project, they faced challenges with bagged items. The distortions caused by plastic bags often blurred key visual features, resulting in misclassifications. This highlighted the need for a more advanced approach to handle complex scenarios. The figure below shows the misclassified example.

Figure 10: Misclassification Image with plastic cover.
ResNet, with its deeper architecture and skip connections, proved to be far more capable in addressing these challenges. By fine tuning the ResNet model on our dataset, we achieved:
Test Accuracy: 78.59%, even with the added complexity of bagged produce.
Improved Classification: ResNet demonstrated superior ability to distinguish items in plastic bags, reducing errors compared to CNNs.
With a Fallback Threshold of 0.6:

Figure 11: Classification of produce using ResNet Architecture.
Figure 11a: Example of a receipt being generated with this program for the above produce.
The above figure shows the ResNet model predictions for six fruits and vegetables in plastic bags. The ResNet model was able to predict 4/6 non-barcoded items. The results captured in the above figure are based on a confidence threshold of 0.6, meaning that the grapes (detected as onions) were classified as onions due to the fact that they were the cheapest alternative at $0.92. However, with the lemons classified as onions, the fallback mechanism was not introduced because the model was confident in its prediction that the lemons were in fact onions. The customer was still undercharged, but this was due to luck, not the fallback mechanism.
With a Fallback Threshold of 0.3:

Figure 12: Classification of produce using ResNet Architecture with varied threshold.

Figure 12a: Example of a receipt being generated with this program for the above (different) produce.
The above figure shows the same ResNet model predictions but at a confidence threshold of 0.3. Lowering the confidence threshold means that the customer is more likely to be overcharged. The grapes (originally classified as onions at $0.92) are now incorrectly classified as garlic, which is $1.08 more expensive than the original prediction. This suggests that the fallback mechanism is working correctly, but highlights the fact that the mechanism will not assist the model in classifying the correct predicted class.
Conclusion: Reflecting on the Progress and Future of ScanSense AI
The ScanSense AI model addressed significant challenges with non-barcoded items in the self checkout lines. The models trained on the original dataset and the augmented datasets proved to be a step in the right direction when it came to classification. The results paint a clear picture: while challenges remain, ScanSense AI is a significant step forward in transforming self-checkout systems. By integrating advanced models like ResNet and employing strategies like fallback thresholds, we’ve developed a solution that not only improves classification accuracy but also mitigates financial risks.
Lessons Learned
While data preprocessing and augmentation are critical for creating a solid foundation, the success of the model heavily depends on the architecture and training techniques employed. The ResNet model demonstrated its superiority in handling complex classification tasks due to its ability to generalize effectively across diverse scenarios. Techniques like dynamic learning rates further emphasized the value of carefully planned training strategies to optimize performance while avoiding overfitting. Additionally, this process highlighted the importance of iterative experimentation and refinement. Finally, we learned the value of evaluating models not only through metrics like accuracy but also by considering their practical implications in real-world use cases.
Future Scope
Despite the progress made, there are several areas for growth. Improving the model’s accuracy, especially in handling complex misclassification scenarios, remains a key focus. A major priority moving forward is to refine the fallback system so it can also address confident misclassifications, further reducing financial impact and bolstering trust. Additionally, expanding the dataset with more diverse and nuanced examples, as well as exploring advanced architectures like Vision Transformers or ensemble approaches, could lead to more accurate predictions.
The advancements achieved through ScanSense AI illustrate the transformative potential of machine learning in self checkouts. While some modifications and improvements could be made, this project has established a strong foundation for future innovation, helping bridge the gap between advanced AI solutions and practical applications in grocery store self checkout lanes.
References and Citations
CBS News, Wharton Business School, Raydiant, and U.S. Bureau of Labor Statistics. "Self-Checkout Shoplifters in the U.S." Capital One Shopping Research, 2024. Available at https://capitaloneshopping.com/research/self-checkout-statistics/
Kritik Seth. "Fruits and Vegetables Image Recognition Dataset." Kaggle, 2021. Available at: https://www.kaggle.com/datasets/kritikseth/fruit-and-vegetable-image-recognition.
He, Kaiming, et al. "Deep Residual Learning for Image Recognition." arXiv, 10 Dec. 2015, arxiv.org/pdf/1512.03385
K. Wankhede, B. Wukkadada and V. Nadar, "Just Walk-Out Technology and its Challenges: A Case of Amazon Go," 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2018, pp. 254-257, doi: 10.1109/ICIRCA.2018.8597403. https://ieeexplore.ieee.org/abstract/document/8597403
 | A guest post by
|
 | A guest post by
|
 | A guest post by
|
 | A guest post by
|